Honestly I am not a blogging person so this kind of seems unnatural to me. Any way I will be using this blog post to write about the stuff I have done and that which I have planning to do.
Some time back I ran some a test bench on the mkjpeg core which was actually a modified version of the test bench provided by mkjpeg.
It turns out that in simulation a 1080 HD pic takes around 50 ms(simulation time) to process which turns out to be 20 fps if the clock has a frequency of 100 MHz. In fact I contacted one of the developer of mkjpeg core and he had this to say:
"I managed to run the ip at 125mhz on a cyclone 4 grade C6.
Because i modified the ip for 4:2:0 compression, it managed to
compress 50mpix/s : 1600x1200 images at 25fps.
I planned to run it at 150Mhz on a arriaV grade c4. At this speed, I
am sure that you can compress 1080p at 30fps with only one ip core."
The mkjpeg core currently has 4:2:2 subsampling which is acceptable in industry but making it 4:2:0 will definitely improve fps with reduction in quality. But the point is if the core can be run a faster rate half the job is done.
So my first step towards optimisation will be trying to improve the max frequency of operation.
Well how will I go about it.
Well the easiest thing to do is try unsing SmartXplorer. SmartXplorer is a xilinx tool which tries different placement and routing strategies to meet the timing requirement. Other things that I am planning to manually locking PLL of jpeg core, changing the timing constraint to make the PAR tool work harder. Changing the fanout constraint can also help.
The slowest block of the mkjpeg core is the HUFFMAN encoder. I will try to add a pipeline stage somewhere in the block to reduce the combinational delay but what I got from the reading the VHDL codes, it seems already there is a lot of pipelining done in the block so it will be tough.
Last week was spent mostly going through the mkjpeg core line by line and believe me it is really tough. Reading some one else's code is always tough but the fact that the core is written in VHDL makes is painful. VHDL is based on ADA and has poor readability. Plus the fact that the language is concurrent makes it extremely tough. Lot of things happen on the same time. But from whatever I did read and managed to understand my respect for the author of the core has increased manifold.
The core uses every trick in the book. It uses pingpong buffers to pipeline each block and FIFO to do data flow pipelining. So the optimisation I thought I could have done seems to be done already.
Also I did investigate about why reading from line buffer stalls.
Well there are two kinds of stall:
1) When fifo are full. The only FIFO that fills up is the one that store DCT values. I haven't investigated this further as the stalls are for few cycles.
2) The second stall is a compulsory stall. The core processes in 16x8 blocks but takes in data in 8x8 blocks.
First, it reads the left 8x8 block pixel by pixel and store it in a RAM called FRAM1. As it is reading the pixel, it is also sending the data for processing of the Y1 component of colour space. This takes 64 cycles.
Then the right 8x8 block is read and stored into FRAM1. Also while is being read, processing of Y2 is being done. This takes another 64 cycle.
Now data for Cr, Cb component are send for processing. There are 128 samples but since 4:2:2 sampling is done, only 64 samples are send for Cr and Cb processing respectively. This takes 128 cycles. And during this 128 cycle no data is being read from the line buffer, hence a stall.
I plan to use this idle 128 cycle to add some extra processing blocks. While Cr, Cb values are getting fed to the DCT block, next 16x8 block can be be read and processed by another DCT block which is then passed onto a new set of zig zag, quantiser block. But the catch is I can't use two Run Length encoder and hence the speed of RLE is critical. So the reading will stop only when pipeline fifos are full.
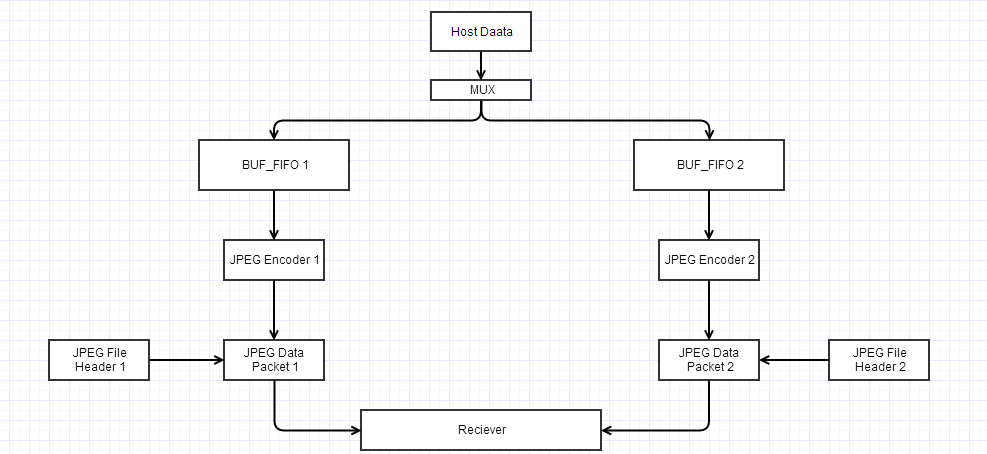
Another idea is a simple brute force technique, use two core instead of one. But the problem is this
Specific Feature Utilization:
Number of Block RAM/FIFO: 77 out of 116 66%
Number using Block RAM only: 77
Number of BUFG/BUFGCTRLs: 13 out of 16 81%
Number of DSP48A1s: 21 out of 58 36%
Number of PLL_ADVs: 4 out of 4 100%
Already 66% of RAM /FIFO resource has been used. The synthesis report of only the JPEG core looks something likes this regarding RAM utilisation:
Specific Feature Utilization:
Number of Block RAM/FIFO: 65 out of 116 56%
Number using Block RAM only: 65
Number of BUFG/BUFGCTRLs: 2 out of 16 12%
Number of DSP48A1s: 10 out of 58 17%
The reason for high utilisation is the highly pipelined nature of JPEG core. Each block has has FIFO for storing intermediate values in a block in addition to ping pong memories for pipelining of each step of encoding. Also a line buffer is used which stores 16 lines of image and is biggest hogger of BRAMs.
Can the algorithms used in the blocks be improved?
I have completely read the codes of DCT, Zig-Zager and Quantiser. It seems the answer is no. Why?
Well DCT core does not use multiplier but ROM based look up table which makes it super efficient. When the pipe line is full, 8x8 blocks are processed in 64 cycles! Quantiser and Zigzager also take 64 cycles when the pipeline is full. This is pretty good. It is very difficult to beat this. Well done Mr Krepa!
I haven't completed reading the RLE and Huffman encoding block hence I can't comment on it right now.
Okay now I am getting bored so will add some more stuff tomorrow. Honestly I am in a sticky situation even before the coding period has started. I guess I should spend more time praying than coding now! :D




{kind=link}